
2. Validation Basics
2.1 Creating train, test, and validation datasets







2.1.1 Create one holdout set
Your boss has asked you to create a simple random forest model on the tic_tac_toe dataset. She doesn’t want you to spend much time selecting parameters; rather she wants to know how well the model will perform on future data. For future Tic-Tac-Toe games, it would be nice to know if your model can predict which player will win.
The dataset tic_tac_toe has been loaded for your use.
Note that in Python, =\ indicates the code was too long for one line and has been split across two lines.
# Create dummy variables using pandas
X = pd.get_dummies(tic_tac_toe.iloc[:,0:9])
y = tic_tac_toe.iloc[:, 9]
# Create training and testing datasets. Use 10% for the test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=1111)
Good! Remember, without the holdout set, you cannot truly validate a model. Let’s move on to creating two holdout sets.
2.1.2 Create two holdout sets
You recently created a simple random forest model to predict Tic-Tac-Toe game wins for your boss, and at her request, you did not do any parameter tuning. Unfortunately, the overall model accuracy was too low for her standards. This time around, she has asked you to focus on model performance.
Before you start testing different models and parameter sets, you will need to split the data into training, validation, and testing datasets. Remember that after splitting the data into training and testing datasets, the validation dataset is created by splitting the training dataset.
The datasets X and y have been loaded for your use.
# Create temporary training and final testing datasets
X_temp, X_test, y_temp, y_test =\
train_test_split(X, y, test_size=0.2, random_state=1111)
# Create the final training and validation datasets
X_train, X_val, y_train, y_val =\
train_test_split(X_temp, y_temp, test_size=0.25, random_state=1111)
Great! You now have training, validation, and testing datasets, but do you know when you need both validation and testing datasets? Keep going! The next exercise will help make sure you understand when to use validation datasets.
2.1.3 Why use holdout sets
It is important to understand when you would use three datasets (training, validation, and testing) instead of two (training and testing). There is no point in creating an additional dataset split if you are not going to use it.
When should you consider using training, validation, and testing datasets?
When testing parameters, tuning hyper-parameters, or anytime you are frequently evaluating model performance.
Correct! Anytime we are evaluating model performance repeatedly we need to create training, validation, and testing datasets.
2.2 Accuracy metrics: regression models






2.2.1 Mean absolute error
Communicating modeling results can be difficult. However, most clients understand that on average, a predictive model was off by some number. This makes explaining the mean absolute error easy. For example, when predicting the number of wins for a basketball team, if you predict 42, and they end up with 40, you can easily explain that the error was two wins.
In this exercise, you are interviewing for a new position and are provided with two arrays. y_test, the true number of wins for all 30 NBA teams in 2017 and predictions, which contains a prediction for each team. To test your understanding, you are asked to both manually calculate the MAE and use sklearn.
from sklearn.metrics import mean_absolute_error
# Manually calculate the MAE
n = len(predictions)
mae_one = sum(abs(y_test - predictions)) / n
print('With a manual calculation, the error is {}'.format(mae_one))
# With a manual calculation, the error is 5.9
# Use scikit-learn to calculate the MAE
mae_two = mean_absolute_error(y_test, predictions)
print('Using scikit-lean, the error is {}'.format(mae_two))
# Using scikit-lean, the error is 5.9
Well done! These predictions were about six wins off on average. This isn’t too bad considering NBA teams play 82 games a year. Let’s see how these errors would look if you used the mean squared error instead.
2.2.2 Mean squared error
Let’s focus on the 2017 NBA predictions again. Every year, there are at least a couple of NBA teams that win way more games than expected. If you use the MAE, this accuracy metric does not reflect the bad predictions as much as if you use the MSE. Squaring the large errors from bad predictions will make the accuracy look worse.
In this example, NBA executives want to better predict team wins. You will use the mean squared error to calculate the prediction error. The actual wins are loaded as y_test and the predictions as predictions.
from sklearn.metrics import mean_squared_error
n = len(predictions)
# Finish the manual calculation of the MSE
mse_one = sum((y_test - predictions)**2) / n
print('With a manual calculation, the error is {}'.format(mse_one))
# With a manual calculation, the error is 49.1
# Use the scikit-learn function to calculate MSE
mse_two = mean_squared_error(y_test, predictions)
print('Using scikit-lean, the error is {}'.format(mse_two))
# Using scikit-lean, the error is 49.1
Good job! If you run any additional models, you will try to beat an MSE of 49.1, which is the average squared error of using your model. Although the MSE is not as interpretable as the MAE, it will help us select a model that has fewer ‘large’ errors.
2.2.3 Performance on data subsets
In professional basketball, there are two conferences, the East and the West. Coaches and fans often only care about how teams in their own conference will do this year.
You have been working on an NBA prediction model and would like to determine if the predictions were better for the East or West conference. You added a third array to your data called labels, which contains an “E” for the East teams, and a “W” for the West. y_test and predictions have again been loaded for your use.
# Find the East conference teams
east_teams = labels == "E"
# Create arrays for the true and predicted values
true_east = y_test[east_teams]
preds_east = predictions[east_teams]
# Print the accuracy metrics
print('The MAE for East teams is {}'.format(
mae(true_east, preds_east)))
# The MAE for East teams is 6.733333333333333
# Print the West accuracy
print('The MAE for West conference is {}'.format(west_error))
# The MAE for West conference is 5.01
Great! It looks like the Western conference predictions were about two games better on average. Over the past few seasons, the Western teams have generally won the same number of games as the experts have predicted. Teams in the East are just not as predictable as those in the West.
2.3 Classification metrics







2.3.1 Confusion matrices
Confusion matrices are a great way to start exploring your model’s accuracy. They provide the values needed to calculate a wide range of metrics, including sensitivity, specificity, and the F1-score.
You have built a classification model to predict if a person has a broken arm based on an X-ray image. On the testing set, you have the following confusion matrix:
| Prediction: 0 | Prediction: 1 | |
|---|---|---|
| Actual: 0 | 324 (TN) | 15 (FP) |
| Actual: 1 | 123 (FN) | 491 (TP) |
# Calculate and print the accuracy
accuracy = (324 + 491) / (953)
print("The overall accuracy is {0: 0.2f}".format(accuracy))
# Calculate and print the precision
precision = (491) / (15 + 491)
print("The precision is {0: 0.2f}".format(precision))
# Calculate and print the recall
recall = (491) / (123 + 491)
print("The recall is {0: 0.2f}".format(recall))
The overall accuracy is 0.86
The precision is 0.97
The recall is 0.80
Well done! In this case, a true positive is a picture of an actual broken arm that was also predicted to be broken. Doctors are okay with a few additional false positives (predicted broken, not actually broken), as long as you don’t miss anyone who needs immediate medical attention.
2.3.2 Confusion matrices, again
Creating a confusion matrix in Python is simple. The biggest challenge will be making sure you understand the orientation of the matrix. This exercise makes sure you understand the sklearn implementation of confusion matrices. Here, you have created a random forest model using the tic_tac_toe dataset rfc to predict outcomes of 0 (loss) or 1 (a win) for Player One.
Note: If you read about confusion matrices on another website or for another programming language, the values might be reversed.
from sklearn.metrics import confusion_matrix
# Create predictions
test_predictions = rfc.predict(X_test)
# Create and print the confusion matrix
cm = confusion_matrix(y_test, test_predictions)
print(cm)
# Print the true positives (actual 1s that were predicted 1s)
print("The number of true positives is: {}".format(cm[1, 1]))
[[177 123]
[ 92 471]]
The number of true positives is: 471
Good job! Row 1, column 1 represents the number of actual 1s that were predicted 1s (the true positives). Always make sure you understand the orientation of the confusion matrix before you start using it!
2.3.3 Precision vs. recall
The accuracy metrics you use to evaluate your model should always be based on the specific application. For this example, let’s assume you are a really sore loser when it comes to playing Tic-Tac-Toe, but only when you are certain that you are going to win.
Choose the most appropriate accuracy metric, either precision or recall, to complete this example. But remember, if you think you are going to win, you better win!
Use rfc, which is a random forest classification model built on the tic_tac_toe dataset.
from sklearn.metrics import precision_score
test_predictions = rfc.predict(X_test)
# Create precision or recall score based on the metric you imported
score = precision_score(y_test, test_predictions)
# Print the final result
print("The precision value is {0:.2f}".format(score))
# The precision value is 0.79
Great job! Precision is the correct metric here. Sore-losers can’t stand losing when they are certain they will win! For that reason, our model needs to be as precise as possible. With a precision of only 79%, you may need to try some other modeling techniques to improve this score.
2.4 The bias-variance tradeoff








2.4.1 Error due to under/over-fitting
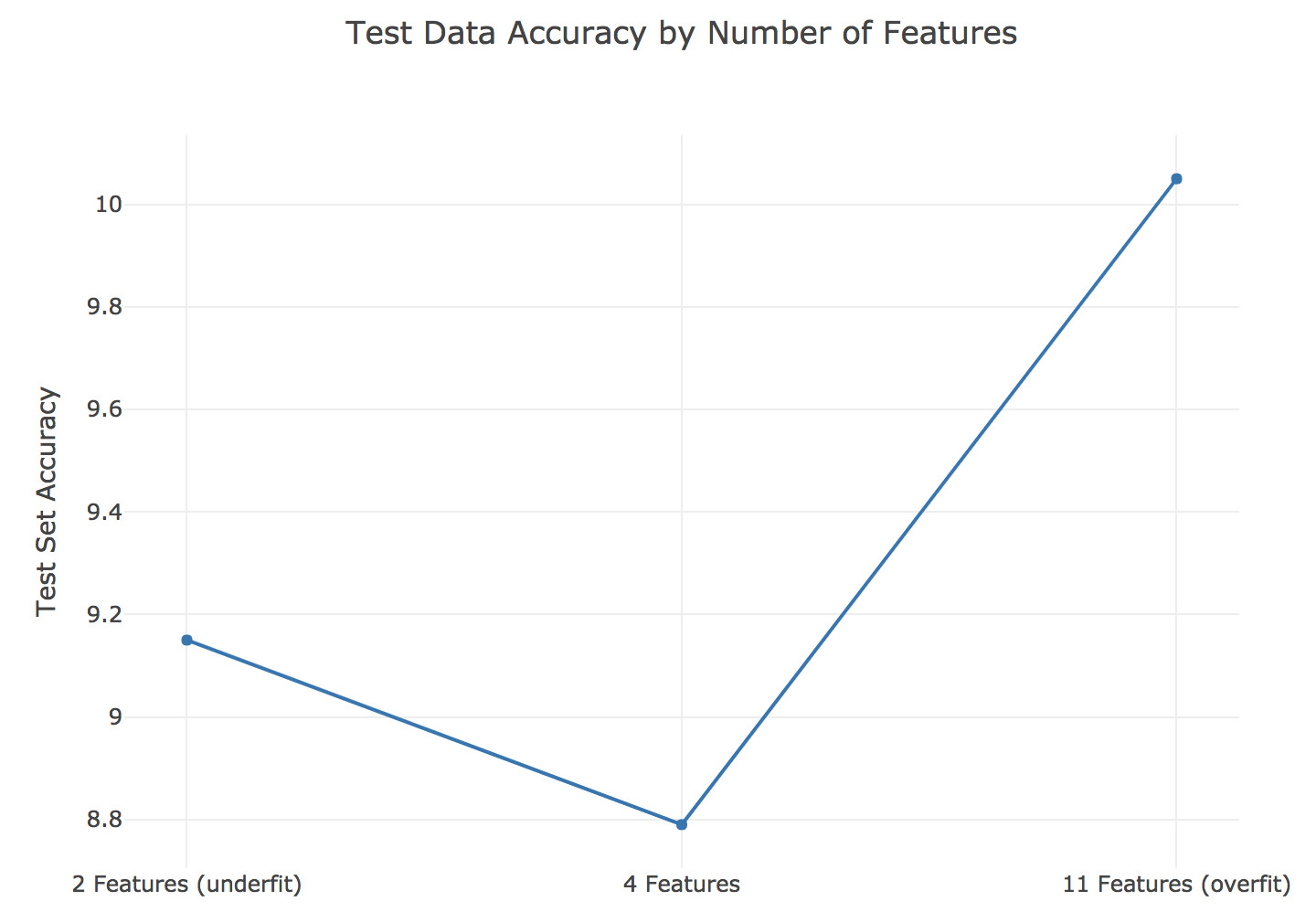
The candy dataset is prime for overfitting. With only 85 observations, if you use 20% for the testing dataset, you are losing a lot of vital data that could be used for modeling. Imagine the scenario where most of the chocolate candies ended up in the training data and very few in the holdout sample. Our model might only see that chocolate is a vital factor, but fail to find that other attributes are also important. In this exercise, you’ll explore how using too many features (columns) in a random forest model can lead to overfitting.
A feature represents which columns of the data are used in a decision tree. The parameter max_features limits the number of features available.
# Update the rfr model
rfr = RandomForestRegressor(n_estimators=25,
random_state=1111,
max_features=2)
rfr.fit(X_train, y_train)
# Print the training and testing accuracies
print('The training error is {0:.2f}'.format(
mae(y_train, rfr.predict(X_train))))
print('The testing error is {0:.2f}'.format(
mae(y_test, rfr.predict(X_test))))
The training error is 3.88
The testing error is 9.15
# Update the rfr model
rfr = RandomForestRegressor(n_estimators=25,
random_state=1111,
max_features=11)
rfr.fit(X_train, y_train)
# Print the training and testing accuracies
print('The training error is {0:.2f}'.format(
mae(y_train, rfr.predict(X_train))))
print('The testing error is {0:.2f}'.format(
mae(y_test, rfr.predict(X_test))))
The training error is 3.57
The testing error is 10.05
# Update the rfr model
rfr = RandomForestRegressor(n_estimators=25,
random_state=1111,
max_features=4)
rfr.fit(X_train, y_train)
# Print the training and testing accuracies
print('The training error is {0:.2f}'.format(
mae(y_train, rfr.predict(X_train))))
print('The testing error is {0:.2f}'.format(
mae(y_test, rfr.predict(X_test))))
The training error is 3.60
The testing error is 8.79
Great job! The chart below shows the performance at various max feature values. Sometimes, setting parameter values can make a huge difference in model performance.
2.4.2 Am I underfitting?
You are creating a random forest model to predict if you will win a future game of Tic-Tac-Toe. Using the tic_tac_toe dataset, you have created training and testing datasets, X_train, X_test, y_train, and y_test.
You have decided to create a bunch of random forest models with varying amounts of trees (1, 2, 3, 4, 5, 10, 20, and 50). The more trees you use, the longer your random forest model will take to run. However, if you don’t use enough trees, you risk underfitting. You have created a for loop to test your model at the different number of trees.
from sklearn.metrics import accuracy_score
test_scores, train_scores = [], []
for i in [1, 2, 3, 4, 5, 10, 20, 50]:
rfc = RandomForestClassifier(n_estimators=i, random_state=1111)
rfc.fit(X_train, y_train)
# Create predictions for the X_train and X_test datasets.
train_predictions = rfc.predict(X_train)
test_predictions = rfc.predict(X_test)
# Append the accuracy score for the test and train predictions.
train_scores.append(round(accuracy_score(y_train, train_predictions), 2))
test_scores.append(round(accuracy_score(y_test, test_predictions), 2))
# Print the train and test scores.
print("The training scores were: {}".format(train_scores))
print("The testing scores were: {}".format(test_scores))
The training scores were: [0.94, 0.93, 0.98, 0.97, 0.99, 1.0, 1.0, 1.0]
The testing scores were: [0.83, 0.79, 0.89, 0.91, 0.91, 0.93, 0.97, 0.98]
Excellent! Notice that with only one tree, both the train and test scores are low. As you add more trees, both errors improve. Even at 50 trees, this still might not be enough. Every time you use more trees, you achieve higher accuracy. At some point though, more trees increase training time, but do not decrease testing error.
